Sling Models offer a very convenient abstraction, as they allow data from the repository being mapped into fields of Java POJO classes. One feature I find often used is the optional InjectionStrategy. By default if an injection is not working, the instantiation of the POJO fails. When the InjectionStrategy.OPTIONAL field is set in the model annotation (see the Sling docs), such a non-working injection will not fail the creation of the model, but instead the field is left with the default value of the respective type. Which is null for Strings and other complex types. And this setting is valid for the entire class, so when you want to write reliable code, you would have to assume that every injected String property could be null.
This comes with a few challenges, because now you can’t rely anymore on values being non-null, but you would need to test each field if a proper value has been provided. Which is sometimes done, but in the majority of cases it is just assumed, that the field is non-null.
I wonder, why this is done at all. Because normally you write your components in a way that the necessary properties are always available. And if you operate with defaults, you can guarantee with several ways that they are available as soon as the component is being created and authored for the very first time. And while for a few cases a missing property must be dealt with for whatever reason, it is never justified to treat all property injections as optional. Because that would mean, that this sling model is supposed to make sense of almost any resource it is adapted from. And that won’t work.
And if a property is really optional: we added some time back the feature to use something like this (if you really can’t give a default value, which would be a much better choice):
@ValueMapValue
Optional<String> textToDisplay;
With this you can express the optionality of this value with the Java type system, and in that case it’s quite unlikely to miss the validation.
But if it would be just be up to me, I would deprecate InjectionStrategy.OPTIONAL and ban it, because it’s one of the most frequent reasons for NullPointer exceptions in AEM.
I know that using InjectionStrategy.OPTIONAL saves you from asking yourself “is this property always present?”, but that’s a very poor excuse. Because with just a few more seconds of work you can make your Sling Model more robust by just providing default values for every injected field. So please:
Avoid using optional injections when possible!
When it’s required use the Optional type to express it!
Don’t use InjectionStrategy.OPTIONAL!
Using “optional” (in all cases) can also come with a performance impact when used with the generic @Inject annotation; for that read my earlier blog posts on the performance of Sling Models: Sling Model Performance.
Sling events are used for many aspects of the system, and initially JCR changes were sent with it. But the OSGI eventing (which the Sling events are built on-top) are not designed for a huge volumes of events (thousands per second); and that is a situation which can happen with AEM; and one of the most compelling reasons to get away from this approach is that all these event handlers (both resource change event and all others) share a single thread-pool.
For that reason the ResourceChangeListeners have been introduced. Here each listener provides detailed information which change it is interested in (restrict by path and type of the change) therefor Sling is able to optimise the listeners on the JCR level; it does not listen for changes when no-one is interested in. This can reduce the load on the system and improve the performance. For this reason the usage of OSGI Resource Event listeners are deprecated (although they are still working as expected).
How can I find all the ResourceChangeEventListeners in my codebase?
That’s easy, because on startup for each of these ResourceChangeEventListeners you will find a WARN message in the logs like this:
Found OSGi Event Handler for deprecated resource bridge: com.acme.myservice
This will help you to identify all these listeners.
How do I rewrite them to ResourceChangeListeners?
In the majority of cases this should be straight-forward. Make your service implement the ResourceChangeListeners interface and provide these additional OSGI properties:
During some recent work on performance improvements in request processing I used a tool, which is part of AEM for a very long time now; I cannot recall a time when it was NOT there. It’s very simple, but nevertheless powerful and it can help you to understand the processing of requests in AEM much better.
I am talking about the “Recent Requests Console” in the OSGI webconsole, which is a gem in the “AEM performance tuning” toolbox.
In this blog post I use this tool to explain the details of the request rendering process of AEM. You can find the detailed description of this process in the pages linked from this page (Sling documentation).
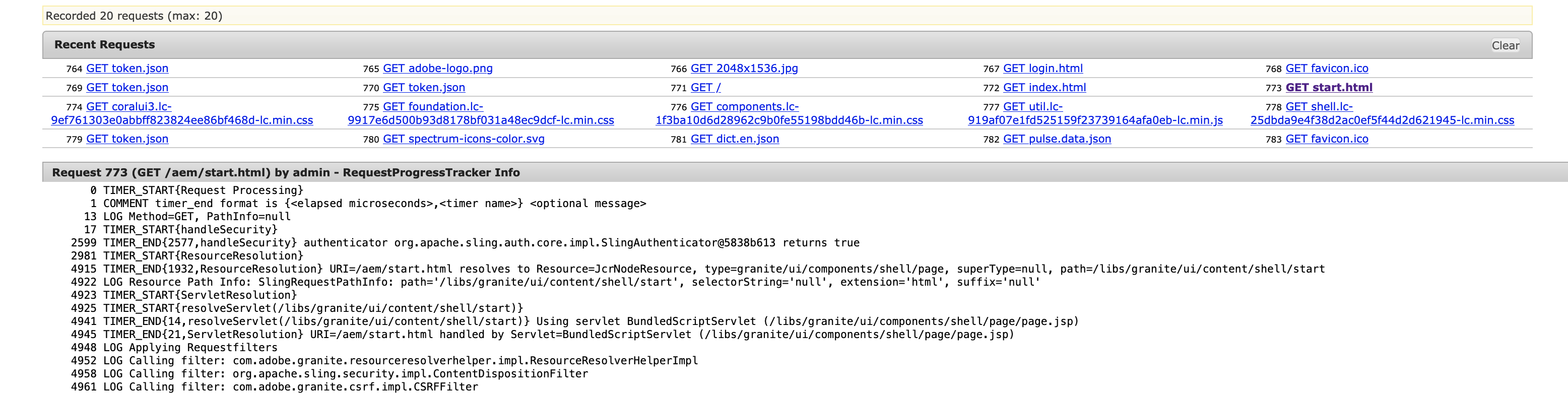
Screenshot “Recent requests”
With this Recent Requests screen (goto /system/console/requests) you can drill down into the rendering process of the last 20 requests handled by this AEM instance; these are listed at the top of the screen. Be aware that if you have a lot of concurrent requests you might often miss the request you are looking for, so if you really rely on it, you should increase the number of requests which are retained. This can be done via the OSGI configuration of the Sling Main Servlet.
When you have opened a request, you will see a huge number of single log entries. Each log entry contains as first element a timestamp (in microseconds, 1000 microseconds = 1 millisecond) relative to the start of the request. With this information you can easily calculate how much time passed between 2 entries.
And each request has a typical structure, so let’s go through it using the AEM Start page (/aem/start.html). So just use a different browser window and request that page. Then check back on the “Recent requests console” and select the “start.html”. In the following I will go through the lines, starting from the top.
Here we see the 2 log lines for a the resolving process of a resourcetype. It took 1932 microseconds to map the request “/aem/start.html” to the resourcetype “granite/core/components/login” with the path being /libs/granite/ui/content/shell/start. Additionally we see information about the selector, extension and suffix elements.
4923 TIMER_START{ServletResolution} 4925 TIMER_START{resolveServlet(/libs/granite/ui/content/shell/start)} 4941 TIMER_END{14,resolveServlet(/libs/granite/ui/content/shell/start)} Using servlet BundledScriptServlet (/libs/granite/ui/components/shell/page/page.jsp) 4945 TIMER_END{21,ServletResolution} URI=/aem/start.html handled by Servlet=BundledScriptServlet (/libs/granite/ui/components/shell/page/page.jsp)
That’s a nested servlet resolution, which takes 14 respective 21 microseconds. Till now that’s mostly standard and hard to influence performance-wise. But it already gives you a lot information, especially regarding the resourcetype which is managing the complete response processing.
These are all request-level filters, which are executed just once per request.
And now the interesting part starts: the rendering of the page itself. The building blocks are called “components” (that term is probably familiar to you) and it always follows the same pattern:
Calling Component Filters
Executing the Component
Return from the Component Filters (in reverse order of the calling)
This pattern can be clearly seen in the output, but most often it is more complicated because many components include other components, and so you end up in a tree of components being rendered.
As an example for the straight forward case we can take the “head” component of the page:
At the top you see the LOG statement “Including resource …” which provides you with the information what resource is rendered, including additional information like selector, extension and suffix.
As next statement we have the resolution of the renderscript which is used to render this resource, plus the time it took (40 microseconds).
Then we have the invocation of all component filters, the execution of the render script itself, which is using a TIMER to record start time, end time and duration (18576 microseconds), and the unwinding of the component filters.
If you use a recent version of the SDK for AEM as a Cloud Service, all timestamps are in microseconds, but in AEM 6.5 and older the duration measured for the Filters (inner=…, outer=…) were printed in miliseconds (which is an inconsistency I just fixed recently).
If a component includes another component, it looks like this:
You see the component filters, but then after the TIMER_START for the page.jsp (check the trailing timer number: #0, every timer has a unique ID!) line you see the inclusion of a new resource. For this again the render script is resolved and instead of the ComponentFilters the IncludeFilters are called, but in the majority of cases the list of filters are identical. And depending on the resource structure and the script, the rendering tree can get really deep. But eventually you can see that the the rendering of the page.jsp is completed; you can easily find it by looking for the respective timer ID.
Equipped with this knowledge you can now easily dig into the page rendering process and see which resources and resource types are part of the rendering process of a page. And if you are interested in the bottlenecks of the page rendering process you can check the TIMER_END lines which both include the rendering script plus the time in microseconds it took to render it (be aware, that this time also includes it too to render all scripts invoked from this render script).
But the really cool part is that this is extensible. Via the RequestProgressTracker you can easily write your own LOG statements, start timers etc. So if you want to debug requests to better understand the timing, you can easily use something like this:
And then you can find this log message in this screen when this component is rendered. You can use it to output useful (debugging) information or just have use its timestamp to identify performance problems. This can be superior to normal logging (to a logfile), becaus you can leave these statements in production code, and they won’t pollute the log files. You just need to have access to the OSGI webconsole, search for the request you are interested and check the rendering process.
And if you are interested, you can can also get all entries in this screen and do whatever you like. For example you can write a (request-level) filter, which calls first the next filter, and afterwards logs all entries of the RequestProgressTracker to the logfile, if the request processing took more than 1 second.
The Request Progress Tracker plus the “Recent Requests” Screen of the OSGI webconsole are a really cool combination to both help you to understand the inner working of the Sling Request Processing, and it’s also a huge help to analyze and understand the performance of request processing.
I hope that this technical deep dive into the sling page rendering process was helpful for you, and you are able to spot many interesting aspects of an AEM system just be using this tool. If you have questions, please leave me a comment below.
A recurring problem I see in AEM project implementations is the problem of missing abstraction. A lot of code deals passes around resources, ValueMaps and even Strings (paths). And because we are supposed to build software the proper way, the called method checks (or more often: not checks) that the provided resource parameter is not null, and that the resource is of the correct type.
But instead of dealing with resources, the class names and comments suggest that the code actually dealing with products. Or website structures. Or assets. But instead of using a “product” classes (or website class, or the provided asset class) still resources are used. The abstraction is missing!
For me the root cause of this problem is the CRXDE Lite. Exactly that thing which you can open on your local AEM instance at /crx/de/. Because it shows you a very nice hierarchical view to the repository, it shows you paths, and properties. And if a developer starts to build a mental model of something, this tool comes in quite handy. Because you can reach everything via path, which is a String! So instead of expressing relations between concepts I see often this:
is much easier to use (and did you spot the off-by-one bug in the String operation example? And what does happen if the path ends already with a slash?). But that still leaves the question, why you need to get the parent resource. Maybe a
is a more expressive way to describe the same. I would definitely prefer it.
So CRXDE is your biggest enemy when designing your application. If you are a seasoned AEM developer, my recommendation to you: Don’t explain your application with CRXDE. Rather use proper abstractions. Don’t do CRXDE driven development!
If that topic sounds familiar to you: I did a talk on the AdaptTo() conference 2020 regarding this topic, you can find the recording here. There I explain the problem in more detail, also including some better examples 🙂
In the last blog post I briefly talked about the basics what to consider when you are writing cluster-aware code. The essence is to be aware of your write activities, and make sure that the scheduled activities are running only on a single cluster node and not on many or all of them.
Today’s focus is on the behavior of JCR sessions with respect to clustering. From a conceptual point of view there is hardly a difference to a single-node cluster (or standalone instance), but the presence of more cluster nodes add a new angle of potential problems to it.
When I talk about JCR, I am thinking of the Apache Oak implementation, which is implemented on top of the MVCC pattern. (The previous Jackrabbit implementation is using a different approach, so this whole blog post does not apply there.) The basic principle of MVCC is that each session is clearly separated from any other session which is open in parallel. Also any changes performed on a session is not visible to other sessions unless
the other session is invoking session.refresh() or
the other session is opened after the mentioned session is closed.
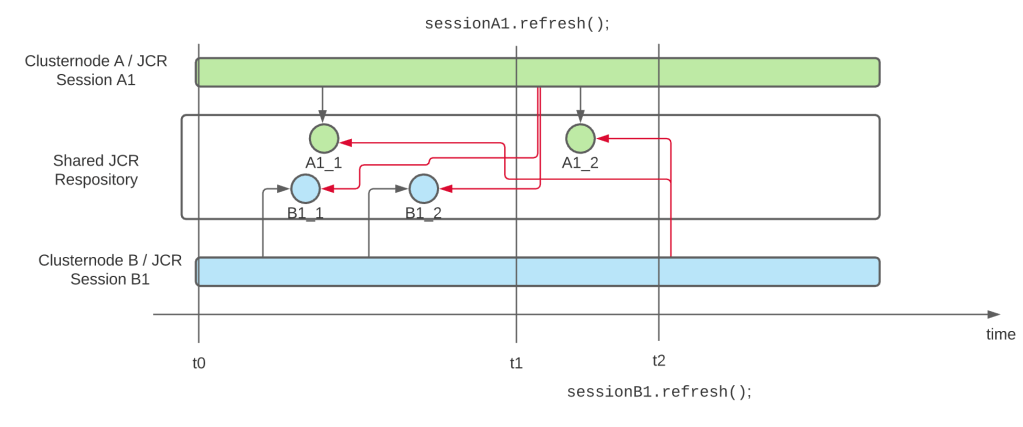
This behavior applies to all sessions of a JCR repository, no matter if the are opened on the same cluster node or not. The following diagram visualizes this
Diagram showing how 2 sessions are performing changes to the repository whithout seeing the changes of the other as long as they don’t use session.refresh()
We have 2 sessions A1 and B1 which are initiated at the same time t0, and which perform changes independently of each other on the repository, so session B1 cannot see the changes performed with A1_1 (and vice versa). At time t1 session A1 is refreshed, and now it can see the changes B1_1 and B1_2. And afterwards B1 is refreshed as well, and can now see the changes A1_1 and A1_2 as well.
But if a session is not refreshed (or closed and a new session is used), it will never see the changes which happened on the repository after the session has been opened.
As said before, these sessions do not need to run on 2 separate cluster nodes, you get the same behavior on a single cluster node as well. But I mentioned, that multiple cluster nodes are a special problem here. Why is that case?
That problem are OSGI services in the background, which perform a certain job and write data to the JCR repository. In a single-node cluster this not a problem, because all of these activities go through that single service; and if that service uses a long-running JCR session for it, that will never be a problem. Because this service is responsible for all changes, and the service can read and write all the relevant data. In a cluster with more than 2 nodes, each cluster node might have that service running, and the invocations of the services might be random. And as in the diagram above, on cluster node A the data A1_1 is written. And on cluster node 2 the data point B1_1 is written. But they don’t see each other’s changes if they don’t refresh the session! And in most applications, which are written for single-node AEM instances, session.refresh() is barely used, because in such situations there’s simply no need for it, as this problem never occurred.
So when you are migrating your application to AEM as a Cloud Service, review your applications and make sure that you find all long-running ResourceResolvers and JCR sessions. The best option is then to remove these long-running sessions and replace them with short-living ones, which are closed if the job is done. The second-best option is to introduce a session.refresh(), so the session sees any updates which happend to the repository in the meanwhile. (And btw: if you registering an ObservationListener in that session, you don’t need a manual refresh, as this refresh is done by the ObservationListener method anyway; what would it be for if not for reporting changes to the repository, which happen after opening the session?)
That’s all right now regarding cluster-aware coding. But I am sure that there is more to come 🙂
With AEM as a Cloud Service quite a number of small things have changed; and next to others you also get real clustering support in the authoring environment. Which is nice, because it gives you downtime-less authoring during deployments.
But this cluster also comes with a few gotchas, and one of them is that your application code needs to be cluster-aware. But what does that mean? What consequences does it have and what code do you have to change if you have never paid attention to this aspect?
The most important aspect is to do “every change only once“. It doesn’t make sense that 2 cluster nodes are importing the same set of data. A special version of this aspect is “avoid concurrent writes to the same node“, which can happen when a scheduled job is kicked off at the same time on all nodes, and this job is trying to change something in the repository. In this case you don’t only have overhead, but very likely a lot of exceptions.
And there is a similar aspect, which you should pay attention to: connections to external systems. If you have a cluster, running the same code and configs, it’s not always wanted that each cluster node reaches out to that external system. Maybe you need to the update it with the latest content only once, because it triggers some expensive processing on their side, and you don’t want to have that triggered two or three times, probably pretty much at the same time.
I have mentioned you 2 cases where a clustered application can be behave differently than a single-node environment, now let me show you how you can make your application cluster-aware.
Scheduled jobs
Scheduled jobs are a classic tool to execute certain jobs at a certain time. Of course we could use the Sling Scheduler directly, but to make the execution more robust, you should wrap it into a Scheduled Sling Job.
See the Sling Jobs website for the documentation and some example (although the Javadocs are missing the ScheduleBuilder class, but here’s the code). And of course you should check out Kaushal Mall’s post with even more examples.
Jobs give you the guarantee, that this job is going to be executed only at least once.
Use the Sling Scheduler only for very frequent jobs (e.g. once every 5 minutes), where it doesn’t matter if one execution is skipped, e.g. because the instance was just restarting. To limit the execution of such a job to a single node, you can annotate the job runner with this annotation:
In-memory caches are often used to speed up operations. Most often they contain the results of previous operations which are then reused; cache elements are either actively purged or expire using a time-to-live.
Normally such caches are not affected by clustering. They might contain different items with potentially different values in the cluster nodes, but that must never be a problem. If that is a problem, you have to look for a different approach, e.g. persisting the data to the repository (if they are not already coming from there) or externalizing the cache (e.g to a redis or memcached instance).
Also, having a simpler application instead of the highest-cache-hit ration possible is often a good trade-off.
Ok, these were the topics I wanted to discuss here. But expect a blog post about one of my favorite topics: “Long running sessions and clustering“.
In the last parts of this small series (part 1, part 2, part 3) I covered some basic approaches how you can use the Sling and AEM mocking libraries to ease writing unittests. The examples were quite basic and focussed, but in reality many test cases turn out to be much more complex.
And especially when your code has dependencies to other OSGI services, tests can get tricky. So today I want to walk you through some unittest I wrote some time ago, it’s a unittest for the EnsureOakIndex functionality (EnsureOakIndexJobHandlerTest).
The interesting part is that the required EnsureOakIndex service references 4 other services in total; if they are not present, my EnsureOakIndex service will never start properly. Thus you have to fullfill all service requirements of an OSGI service in the unittest as well (at least if you want to use SlingContext like I do here).
The easiest way to solve this is to rely on predefined services which are part of the SlingMocks or AemMocks. The second best way is to create simple mocks and register them a service, so the dependency is fulfilled. That’s definitely a convenient way if your tests do not invoke any of the service methods at all.
Thus the setup() method of my unittests are often pretty large, because there I prepare and inject all other services which I need to make my software-under-test work.
And because this setup works quite well and reliably, I always use AemContext for my unittests (or SlingContext, but as I haven not yet observed any difference in test execution time, I often prefer just AemContext because it comes with some more sevices). Just if I don’t need resources, nodes and no OSGI, I stick with plain junit. For everything else AemContext removes the necessity for mocking a lot.
I introduced SlingMocks in the recent blog posts (part 1, part 2), and till now we only covered some basics. Let’s dig deeper now and use one of its coolest features: Mocking resources.
Well, to be honest, we don’t mock resources. We do something much better: We build an in-memory structure which represent sling resources. We can even map that to an in-memory JCR-repository!
For this blog post I created a very simple Sling model, which supposed to build a classic navigation. For simplicity I omitted nearly all of the logic which makes up a production-ready navigation component, and want to add just the pages below the site root to it.
The interesting part is the unit test. This time I used the AemMocks library from wcm.io, because it provides all the magic of the SlingMocks, plus some AEM specific objects I would like to use. As the AemContext class inherits directly from the SlingContext class, we can just use it as a drop-in replacement.
Loading the test data from a JSON flle in the test resources
The setup method is very simple: It loads a JSON structure and populates a in-memory resource tree with it (adds everything below a resource “/content”). Using this approach there’s no longer the need to mock resources, properties/value maps, and mock the relation between these. This is all done by the SlingMocks/AemMocks framework.
Thus a testcase looks like this:
No boilerplate code anymore
This simple example shows how easy it can be to write unit tests. The test code is very concise and easy to read and understand. In my opinion the biggest issue when writing unit tests now is creating the test content 🙂
Some notes to the test content:
My personal style is to put the test content into the same structure than the java packages. This makes it very easy to find the testcontent and keeps the testcontent and the unittest together.
You can write the JSON manually. But you can also use CRXDE Lite to create some structure in your local AEM instance and then export it with “http://localhost:4502/content/myproject/testcontent.tidy.-1.json ” and paste it into the JSON file. I find this way much more convenient, especially if you already have most of the test content ready. But if you do that, please clean up the unnecessary properties in the test data. They are polluting the test content and make it harder to understand.
In the previous post I showed you how easy it is to start using SlingContext. If you start to use this approach in your own project and just copy the code, your Maven build is likely to fail with messages like this:
[ERROR] testActivate_unconfiguredParams(de.joerghoh.cqdump.samples.unittest.ReplicationServletTest) Time elapsed: 0.01 s <<< ERROR! org.apache.sling.testing.mock.osgi.NoScrMetadataException: No OSGi SCR metadata found for class de.joerghoh.cqdump.samples.unittest.ReplicationServlet
at org.apache.sling.testing.mock.osgi.OsgiServiceUtil.injectServices(OsgiServiceUtil.java:381)
The problem here is not the use of the SlingMock library itself, but rather the fact that we use SlingMocks to test code which uses OSGI annotations. The fix itself is quite straight-forward: We need to create OSGI metadata also for the unittests and not only for the bundling (SlingMock is reading these metadata for the test execution).
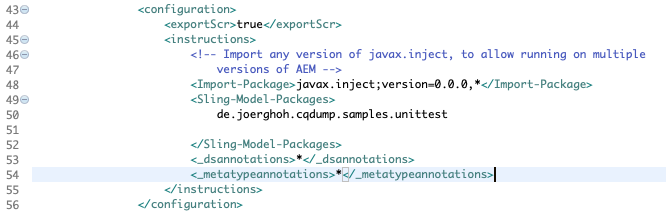
That’s the reason why there’s the need to have a dedicated execution definition for the maven-bundle-plugin:
Also you need to instruct the maven-bundle-plugin to actually export the generated metadata to the filesystem using the “<exportScr> statements; this should be the default in my opinion, but you need to specify it explicitly. Also don’t forget to add the “_dsannotation” and “_metatypeannotations” statements to its instruction section:
Ok, if you adapted your POMs in this way, your SlingMock based unittests for OSGI r6-based services should run fine. Now you can start exploring more features of SlingMocks.
Over the course of the last years the tooling for AEM development improved a lot. While some years ago there was hardly an IDE integration available, today we have dedicated tools for Eclipse and IntelliJ (https://helpx.adobe.com/experience-manager/6-4/sites/developing/using/aem-eclipse.html). Also packaging and validation support was poor, today we have the opensourced filevault and tools like oakpal (thanks Marc!)
But with SlingMocks we also have much better unittest tooling (thanks a lot to Stefan Seifert and the Sling people), so we much more and better/easier tooling than just Mockito and Powermock. SlingContext (and its extension AemContext) allows you create unit tests quite easily. Using them can help you get rid of mocking Sling Resources, repo access and many things more.
On top of that, SlingMock can easily work with the new OSGI r6 annotations, which allow you to define OSGI properties in Pojos. Mocking the @ObjectClassDefinition classes isn’t that easy, because they are essentially annotations …
To illustrate that, I have created a minimal demo with a servlet and testcases for it (source code at Github). Basically the functionality of the class itself is not relevant for this article, but we want to focus on aspects how you utilize the frameworks best to avoid boilerplate code.
The code is quite simple, but to make unittesting a bit more challenging, it uses the new OSGI r6 annotations for OSGI configuration (using the @Designate and the @ObjectClassDefinition annotations) plus a referenced service.
If you try to mock the ReplicationServlet.Config class the naive way, you will find out, that it’s an annotation, which is referenced in the activate() method. I always failed to mock it somehow, so I switched gear and started to use SlingMock for it. (I don’t want to say that it is not possible, but it’s definitly not straight-foward, and in my opinion writing unit-tests should be straight forward, otherwise they are not created at all.)
With SlingMocks the approach changes. I am not required to create mocks, but SlingMocks provides a mocked OSGI runtime we can use. That means, that we create the OSGI parameters as a map to tell the SlingContext object to register our service with these parameters (line 59).
Because SlingContext implements quite a bit of the OSGI semantics, it also requires that all referenced services are available (if these are static references). Therefor I use Mockito to mock the Replicator and I register the mock to provide the Replicator service. In realworld I could verify the interactions of my servlet with that mock.
This basic example illustrates how you can use SlingMocks to avoid a lot of mocking and stubbing. This example does not utilize the full power of SlingMocks yet, we are just scratching at the surface. But we already have some benefit : If you switch from SCR annotations to OSGI annotations, your SlingMock unittests don’t need any change, because it provides an OSGI-like environment, and there the way how metatypes are generated and injected are abstracted away.


: OSGI services mock services")


: Mocking resources")


: Maven Setup")






You must be logged in to post a comment.